
Born Different: How AI Natives Build Startups
A new generation of founders is shipping with smaller teams, moving faster, and using AI across every function.
Meet the top AI infrastructure minds where architects of AI share what actually works. Announcing 2027 dates soon!




















A decade of infrastructure expertise.
Look back at insights from this year's talks. Deep dives into the architectures and tools that defined the year.
A new generation of founders is shipping with smaller teams, moving faster, and using AI across every function.

The new bottleneck isn't compute—it's high-quality environments for post-training agents. This panel explores what it takes to build them at scale, from infrastructure reliability to long-horizon reasoning.

Why fine-tuning is quietly resurging as "RL," how teams are compressing inference costs with smaller specialized models, and who owns the model routing problem.

Why do some AI applications deliver and others totally bunk? A look at LLM history, mystery, and optimization—and where the f**k all the automation actually went.

AI has rewritten the requirements for data infra—latency, compute separation, vector workloads, real-time inference. Three engineers debate what's changing under the hood and what's next.

Mozilla CTO Raffi Krikorian says the internet's security detente is over. He and Pete Soderling dig into AI as co-author, open source economics, and if open models can rival frontier labs.
Learn from the engineers at OpenAI, NVIDIA, and Anthropic who are moving the industry forward.











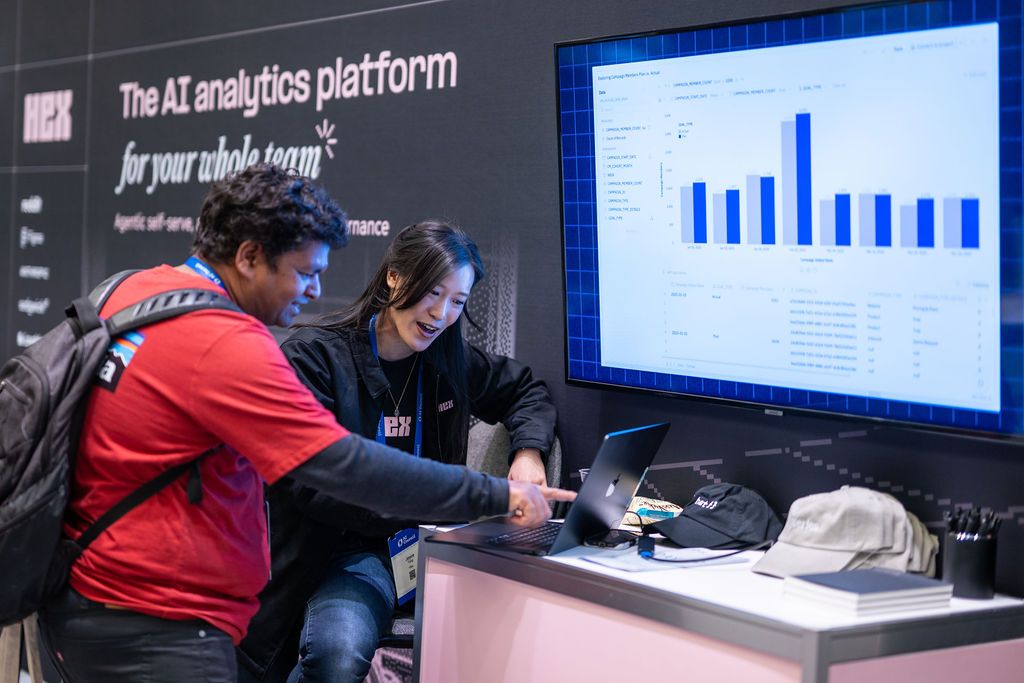






AIC provides an intimate setting for interacting with other folks in the industry, whereas other conferences you may not know anyone you meet in the hallways.
Ryan Boyd, Co-Founder, MotherDuck
years of engineering history
expert-led sessions
technical attendees



